
Agile Requirements Management Part 3 – A Collaborative Data Model
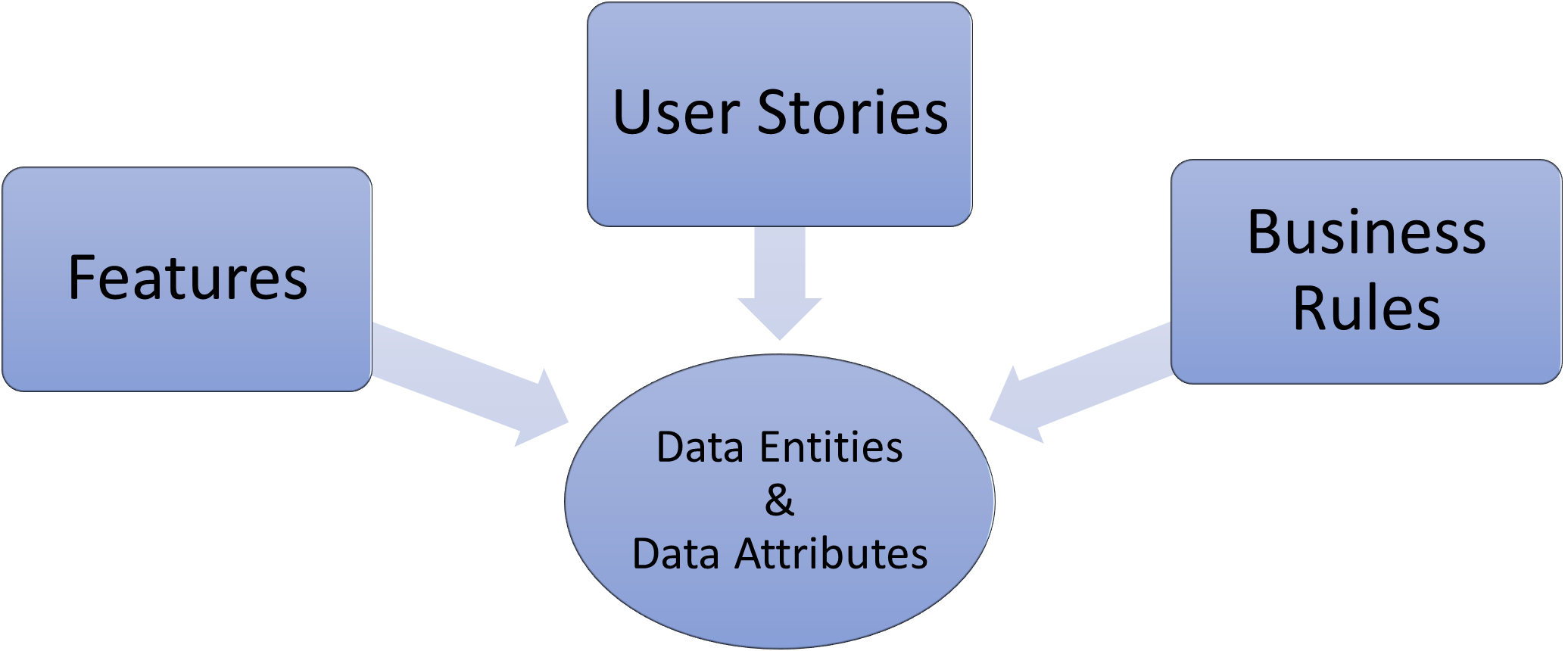
In this article I want to explore how to integrate data requirements with product features and user stories; the result is some very useful traceability to where a particular data entity or attribute is being used across a product.
A conceptual data model is an integral part of the analysis process, it allows the analyst to better understand the overall requirement and how the various elements are related to each other. This enables the correct features to be identified to support the requirement and may well identify some gaps in the requirement where data is not being setup ready for the next process to collect and consume.
The data model will then naturally provide the start point for the database design and will ensure that all the features and associated user stories are all be singing from the same hymn sheet. The sprint teams will benefit from a shared understanding of the data that they are being tasked to manage.
The Tool
Initially my thoughts were that a true data modelling tool with a built-in dictionary were needed, having used these kinds of tools in previous projects.
As the choice of tool was limited, we explored whether Confluence might provide a useful stand in solution; we were already using Confluence to manage the requirements and user stories, so this looked like a natural plug-in to our existing Confluence wiki.
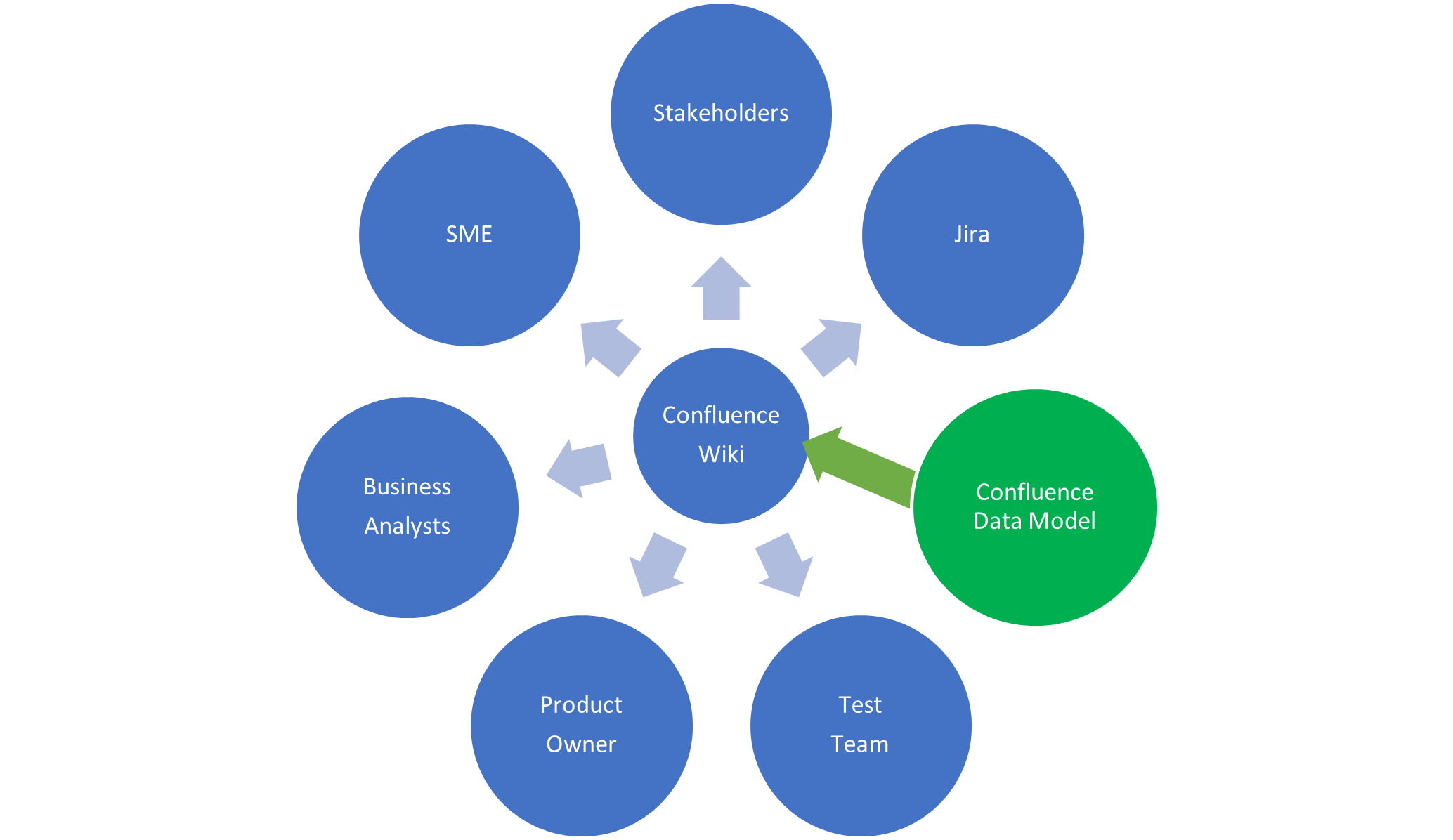
Develop the Model
For convenience, a separate data modelling space was setup to hold all the diagrams and page content for the data model which could then be referenced across the Wiki pages to add understanding to the requirements.
The Confluence service we were using came with the Gliffy diagramming tool; this allowed us to create entity relationship diagrams (class models). As the model was quite large, it was split into distinct data domains, this is easily managed by creating a view (diagram) for each domain.
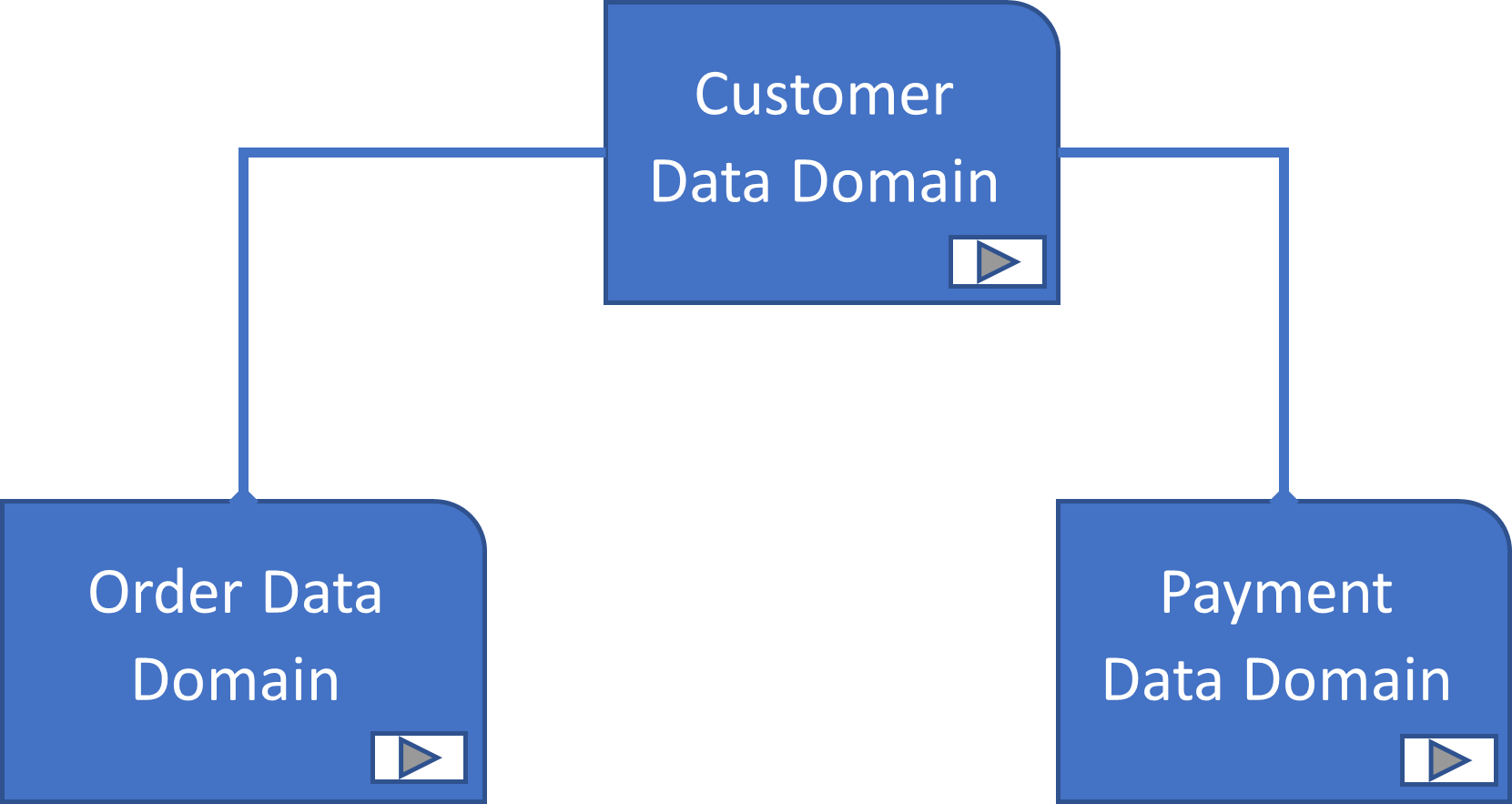
Create Data Entities
In order to make the Confluence data model more like a true tool-based model, hyperlinks were included in the diagrams attached to drawing objects like an entity or domain; click on a high-level domain in the diagram view and the attached URL will then launch the associated domain view diagram, allowing a drill down to the detailed entity level.
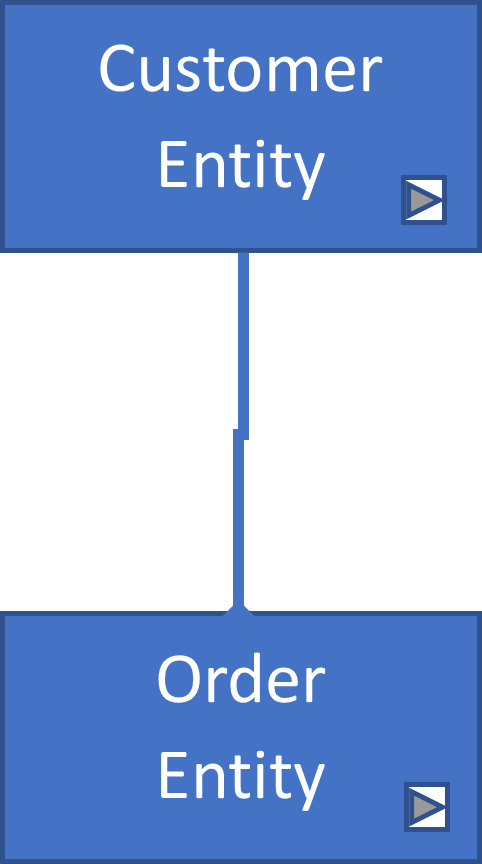
Once down at the entity level, the next step is to setup each entity as a separate Confluence page; the last click at the entity level will arrive on a page that can be enriched with content for collaboration with the team.
Each data entity is loaded as a separate Confluence page; this approach also means that you can link to individual features and user stories using the page URL but also provides a ready-made folder to hold related content like data attributes.
Advertisement
Tip – Setup Data Domains
Setup a domain hierarchy in Confluence to file the entities appropriately, this will facilitate creating views of subsets of the model using the ancestor filter option in the reporting macro.
Trace Data Requirements
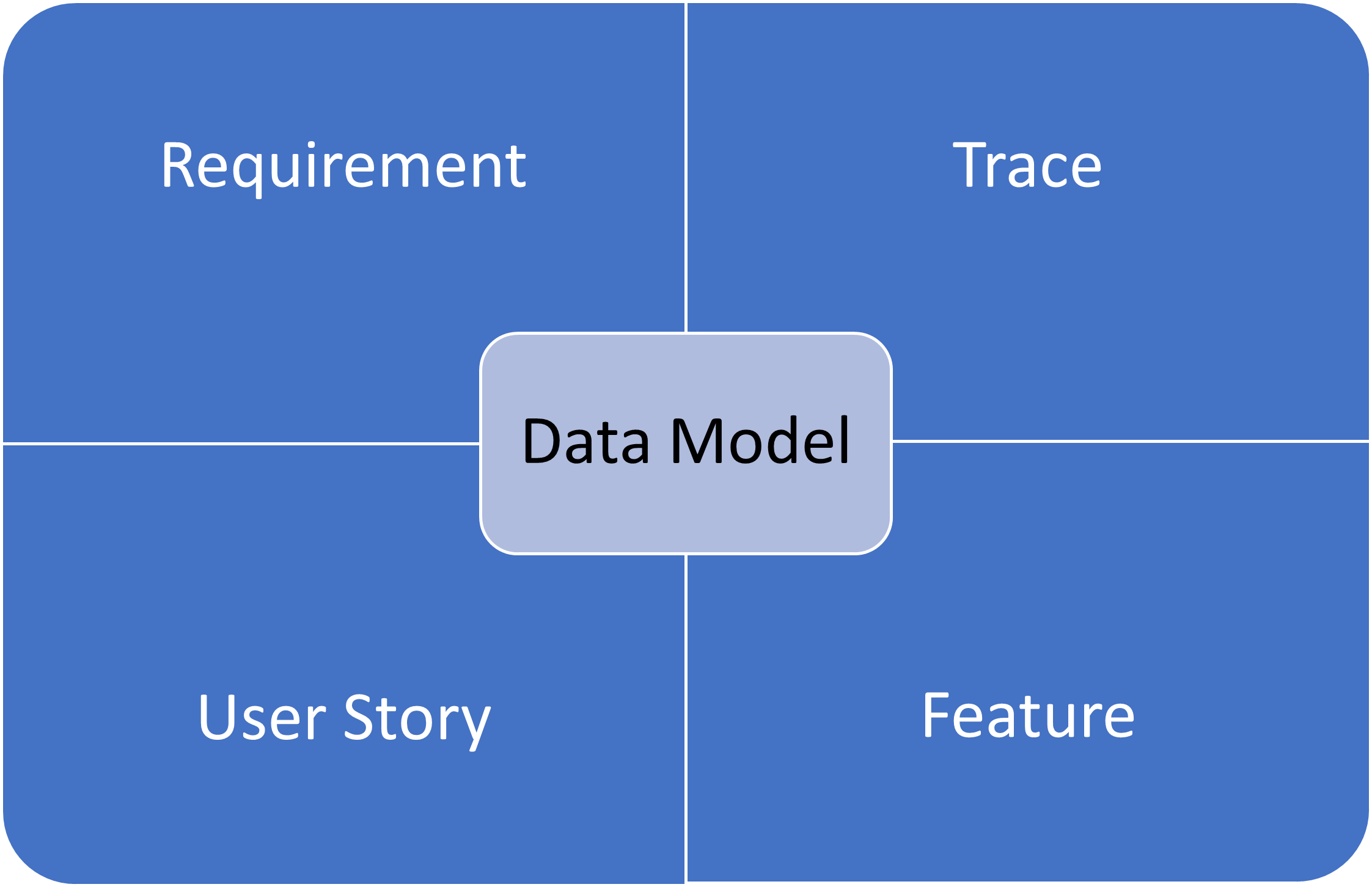
Now we have the model available in Confluence with each entity loaded as a separate page the data requirement can be integrated into the requirements wiki traced to the product features and included in user stories as a URL link to the relevant pages.
Tip – Identify Data Usage
The more comprehensive the application of this approach the greater value will be realised; if you go down to attribute pages then it will be possible to drill down to where data items are being processed.
Setup Data Attributes
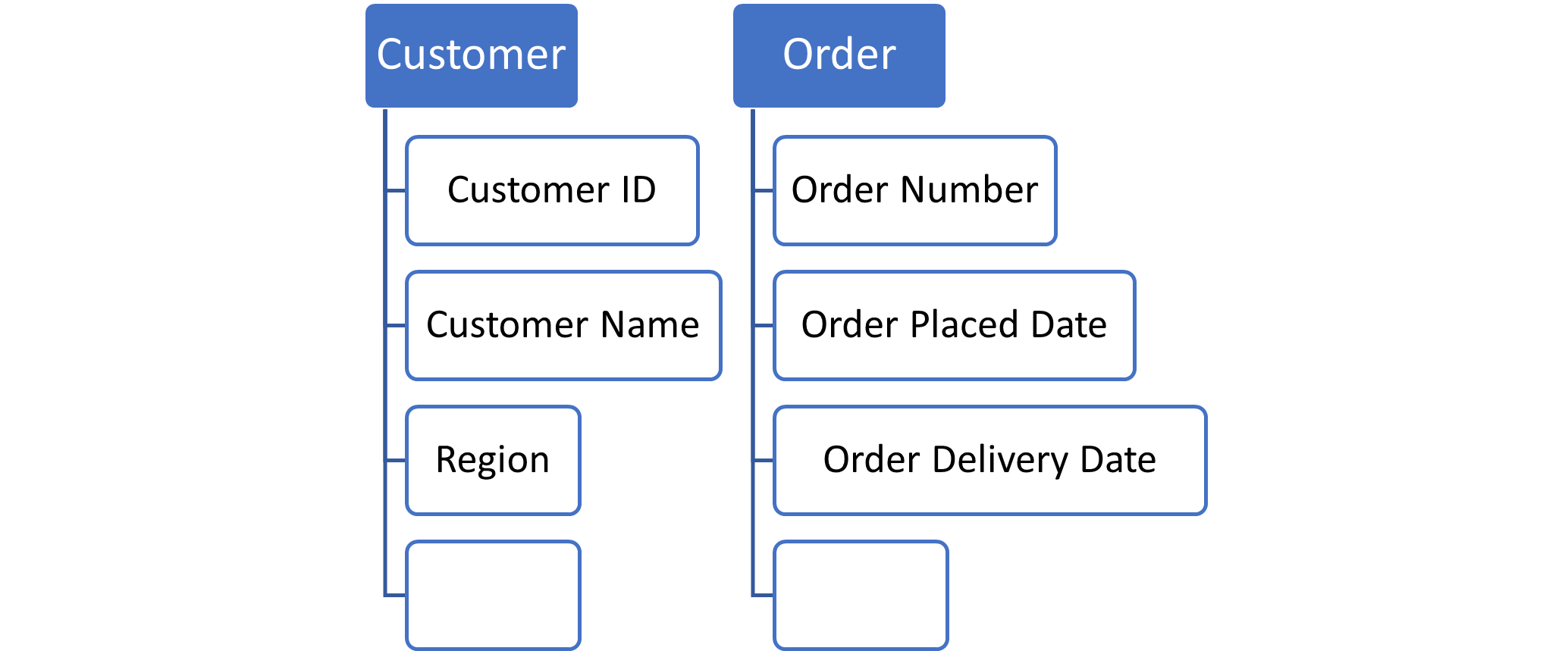
Defining the data attributes is a useful activity to ensure that the system will include all the required data and manage it in a consistent manner.
Data attributes can be simple and self-explanatory items, the name alone can be enough to understand the purpose intended; however, it is often the case that the meaning can be very subtle and having an attribute page available to record an explanation is very useful.
Data attributes are setup as child pages to the parent data entity page to provide a natural filing plan but they can be referenced anywhere and shared in conversations with team members to clarify their purpose and ensure consistent data usage.
Tip – Attribute Names
Page names must be unique within a Confluence space, so it is a good idea to fully qualify the page name with the entity name as a prefix to avoid any duplication issues across different entities.
Integrate Data Requirements
This is where the data model becomes integrated and collaborative, a big advantage over separate modelling tools.
Whenever a user story is referencing a data requirement then the URL to the entity page can be plugged into the story as part of the narrative. For example, the narrative “Create a Customer record for the order received” can replace the plain text “customer” with a URL to the customer entity page instead. Once this approach is adopted the data usage can easily be discovered; starting from the entity page under the page information details all the incoming and outgoing links to the page will be shown, revealing where the data is used and with a single click the reader can jump straight to the story page.
Tip – Business Rules
Including attribute links in business rules will ensure the sprint teams are looking in the right place when implementing the user stories. For example, check the “order delivery date” has not be missed; otherwise, an alert must be triggered to follow-up on the delay with the customer.
Conclusion
Confluence may not appear to be the obvious tool to consider for managing data requirements; however, the fact that it can be integrated with the product features and user stories is quite powerful. The ability to see where individual data attributes are being used facilitates impact analysis and support; the business rules can be expressed precisely and facilitate the development of an integrated system.
It will require careful management to ensure changes can flow through the process and can easily be identified but this is true of all these kinds of tools.
Last but not least is a the record of feedback and comments added to the pages in Confluence, explaining why certain decisions were made and how data attributes introduced are being used by the system. This record will be invaluable for assurance and support queries to understand the how and why a piece of data is being used by the system.