Use Case or User Story
An interesting question! Do we stick with use cases or switch to agile user stories as the best way to model, understand and deliver requirements?
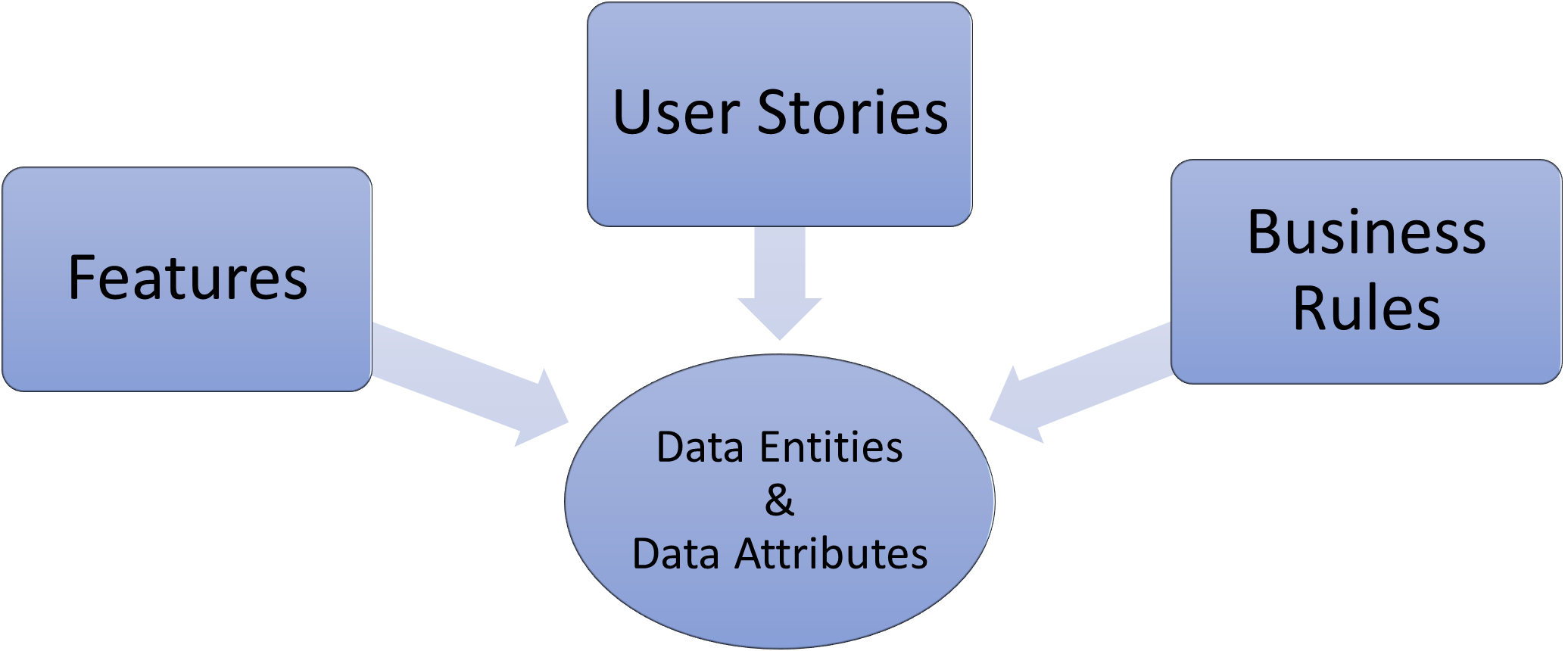
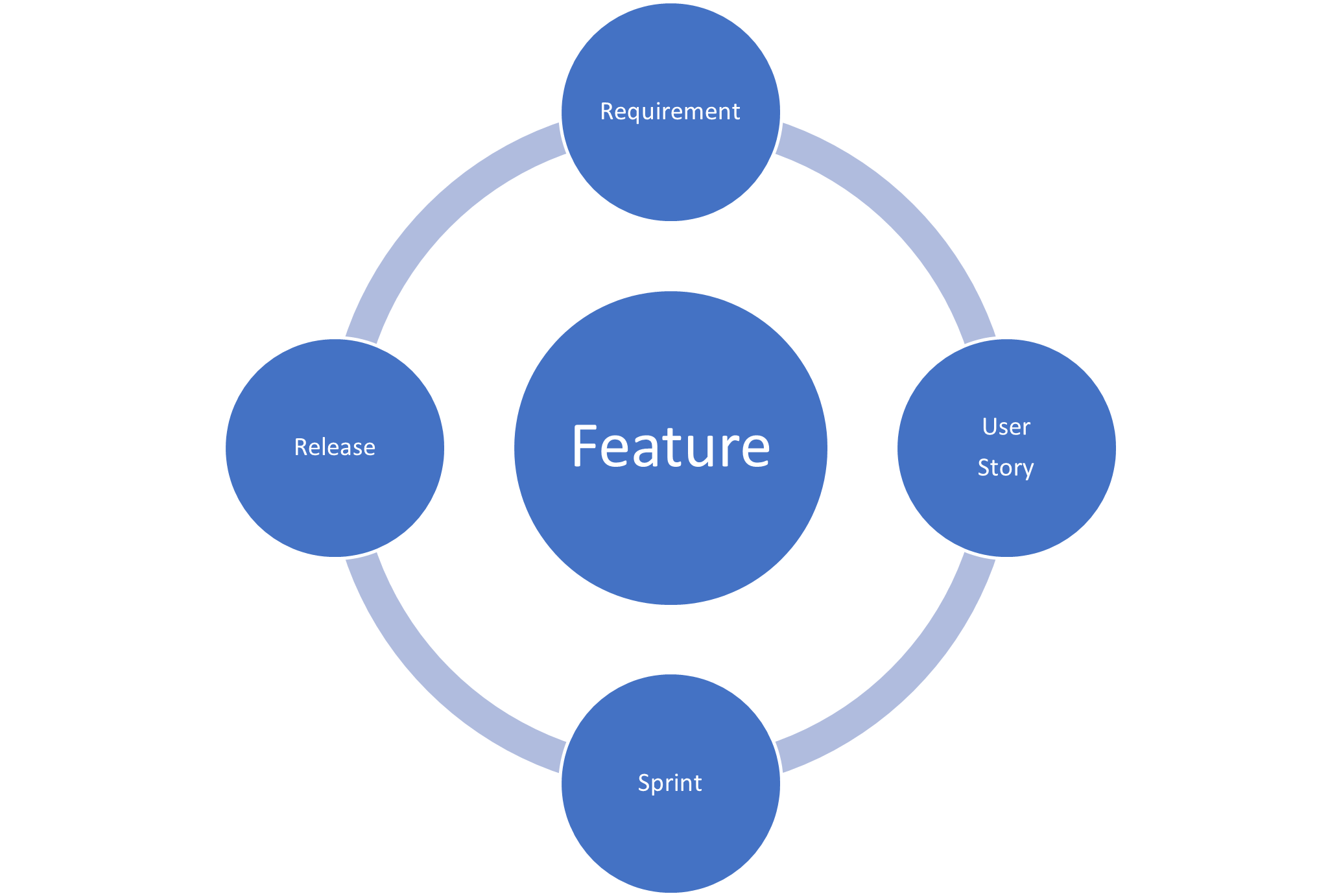
The answer is to apply both techniques and together they work well to complement each other. In this approach, I view the use case as a business use case focused on business actions and processes; the user story is focused on the system requirements elaborating what is required of the system to support the business use case and supporting the agile sprint development process.
Use Cases
The objective of the use case in this context is to communicate the understanding of the requirement to the SMEs and stakeholders to ensure that the correct solution will be developed. It won’t be fool proof, but it should help steer the development in the right direction; until the first show and tell session, you can never be absolutely sure the requirement has been fully understood.
I would restrict the use case content to be only that essential to explain how the requirement will be delivered; alternate flows etc should be pushed into the use stories as far as possible. It may well be useful to expose some draft business rules for discussion as part of the use case but keep in mind the rules will need to be included and implemented via the user stories.
The Tool
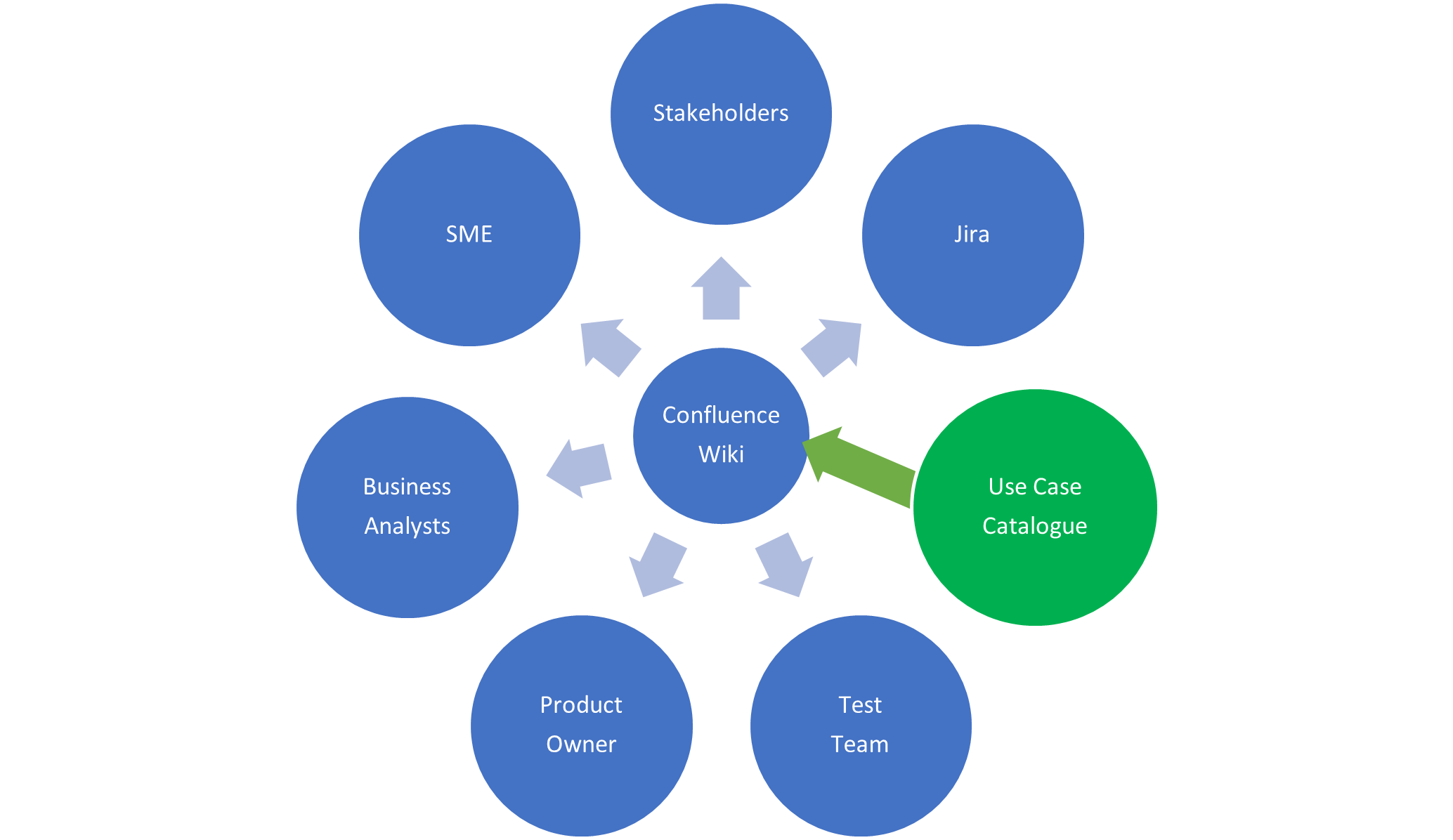
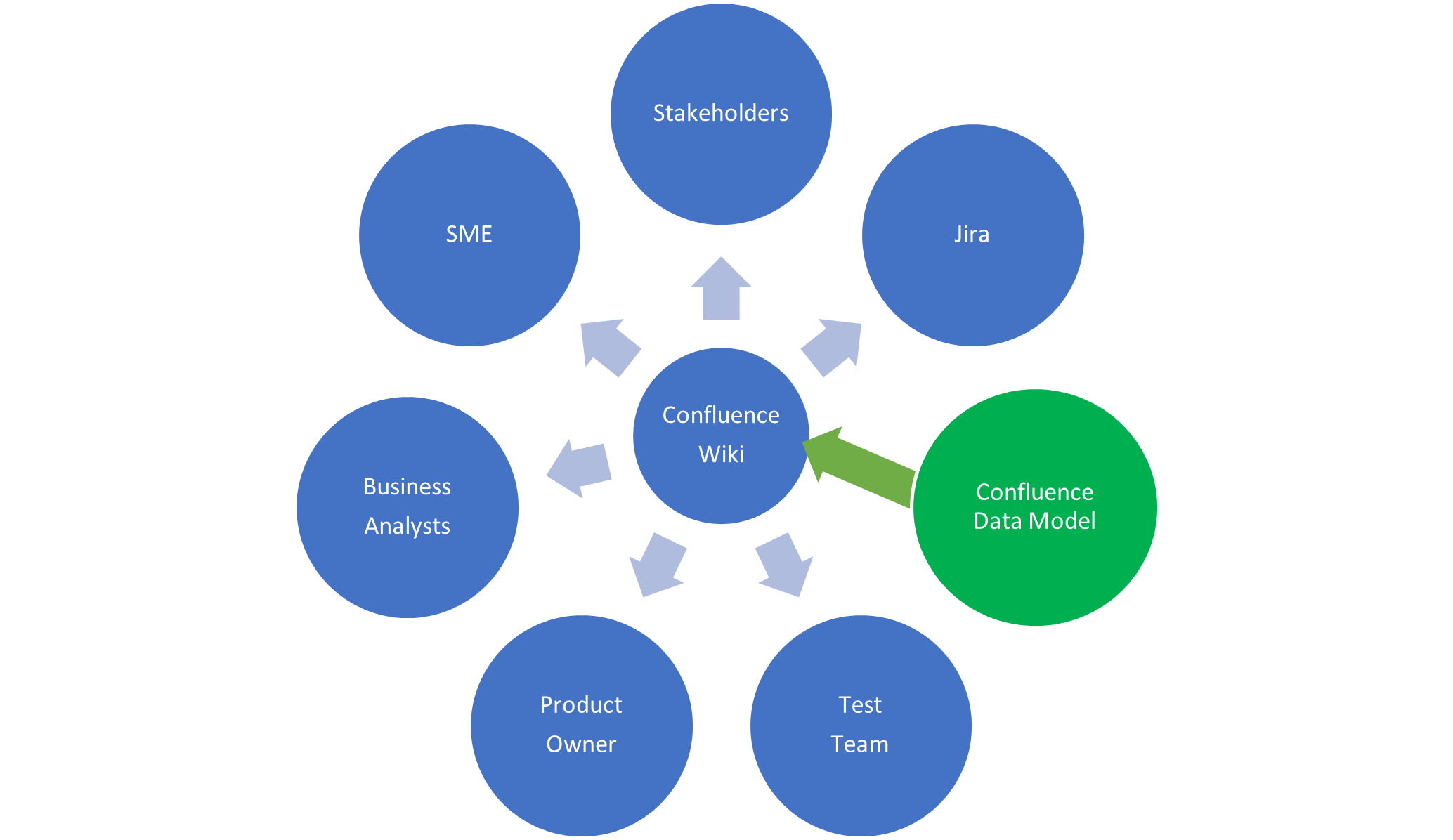
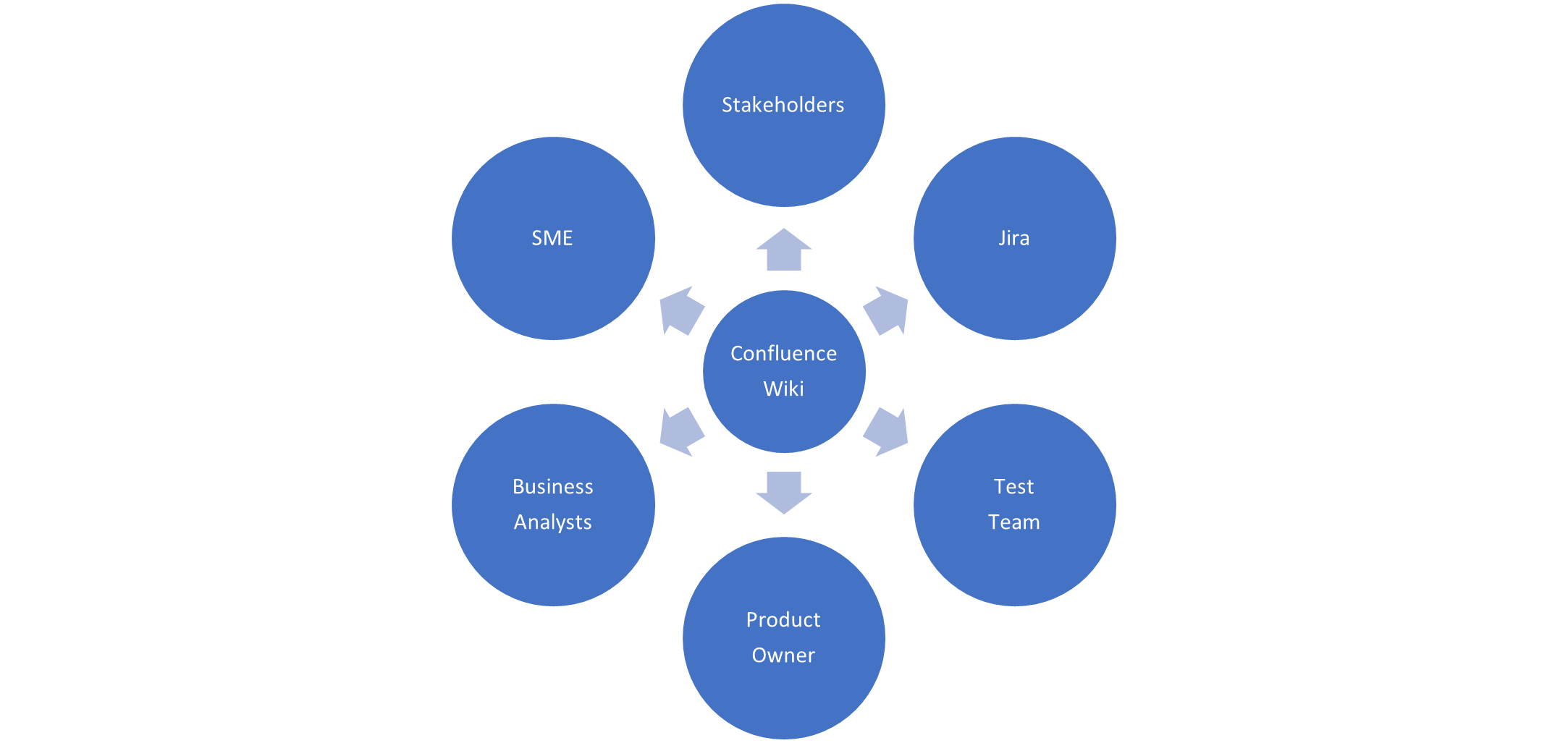
We had already setup a wiki using the Atlassian Confluence tool, the logical step was to extend the existing wiki and introduce a fairly simple template for our use case pages; different tools could be adopted, even PowerPoint would work. Using Confluence allowed existing content to be linked directly into our use case pages as needed; it also includes a presentation mode allowing page content to be used directly in a presentation and exported to PDF or Word format documents.
The use cases can then be used to present back to the SMEs and stakeholders to confirm the understanding of requirements and the validity of the proposed process.
Tip – Catalogue Use Cases
It is useful to have index of all the use cases that includes a status to show work in progress, which ones have been published and those reviewed with SMEs. We managed our use case catalogue within Confluence using custom decision pages to provide an index view of all the cases.
User Stories
The key differentiator with the story is that it targets a specific system requirement and product feature, explaining a feature to an SME is a valid activity but without the context of the overall process, it might be a hard sell. Typically, you will need to introduce some supporting product features which may not be immediately obvious to SMEs; hence combining the stories together into a coherent business process will help SMEs to understand the overall solution context.
User stories can be identified but not elaborated depending on the level of confidence in understanding for a given requirement and business process. It may be appropriate to propose a change based on the understanding prior to a workshop or it might be better to get feedback from the workshop and then work on the stories with the knowledge gained.
The objective is to gain confidence in the understanding of a requirement so that everything can proceed down the right track with a joined-up set of product features.
Tip – Catalogue User Stories
A template for developing user stories can be adopted, this is useful as a prompt for details which may be appropriate e.g., what’s the existing feature doing currently and what needs to be changed. We managed our use story catalogue within Confluence using custom decision pages to provide and index view.
Advertisement
Joined Up Thinking
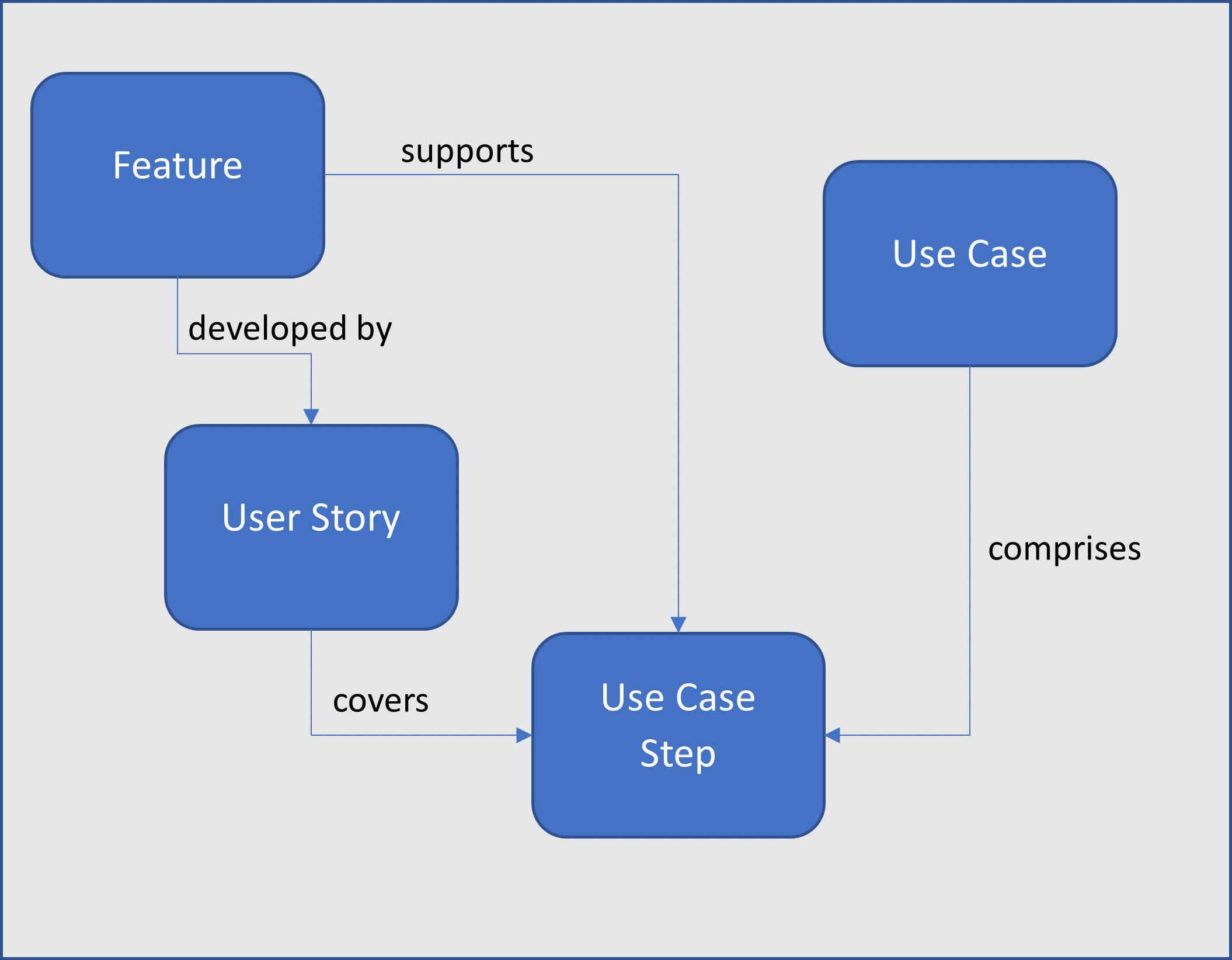
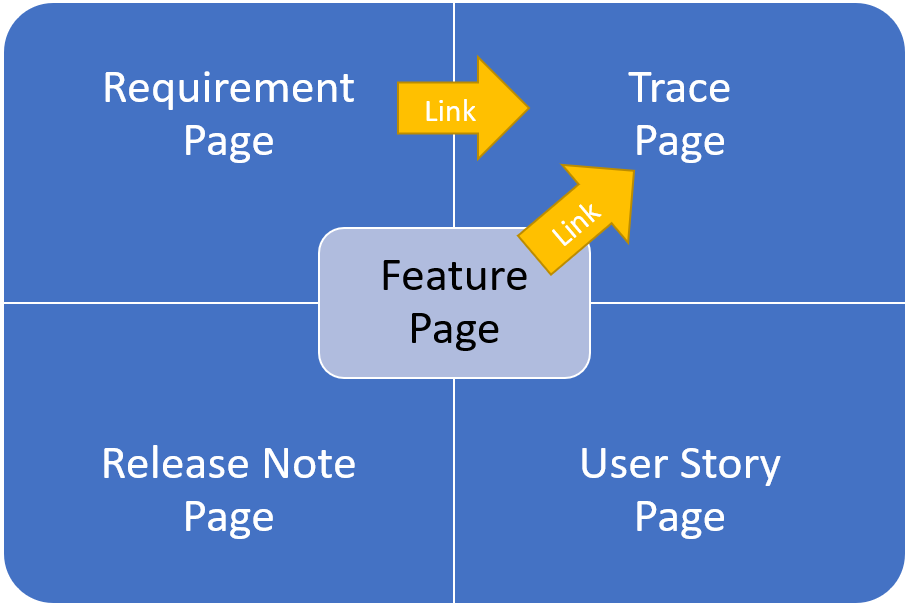
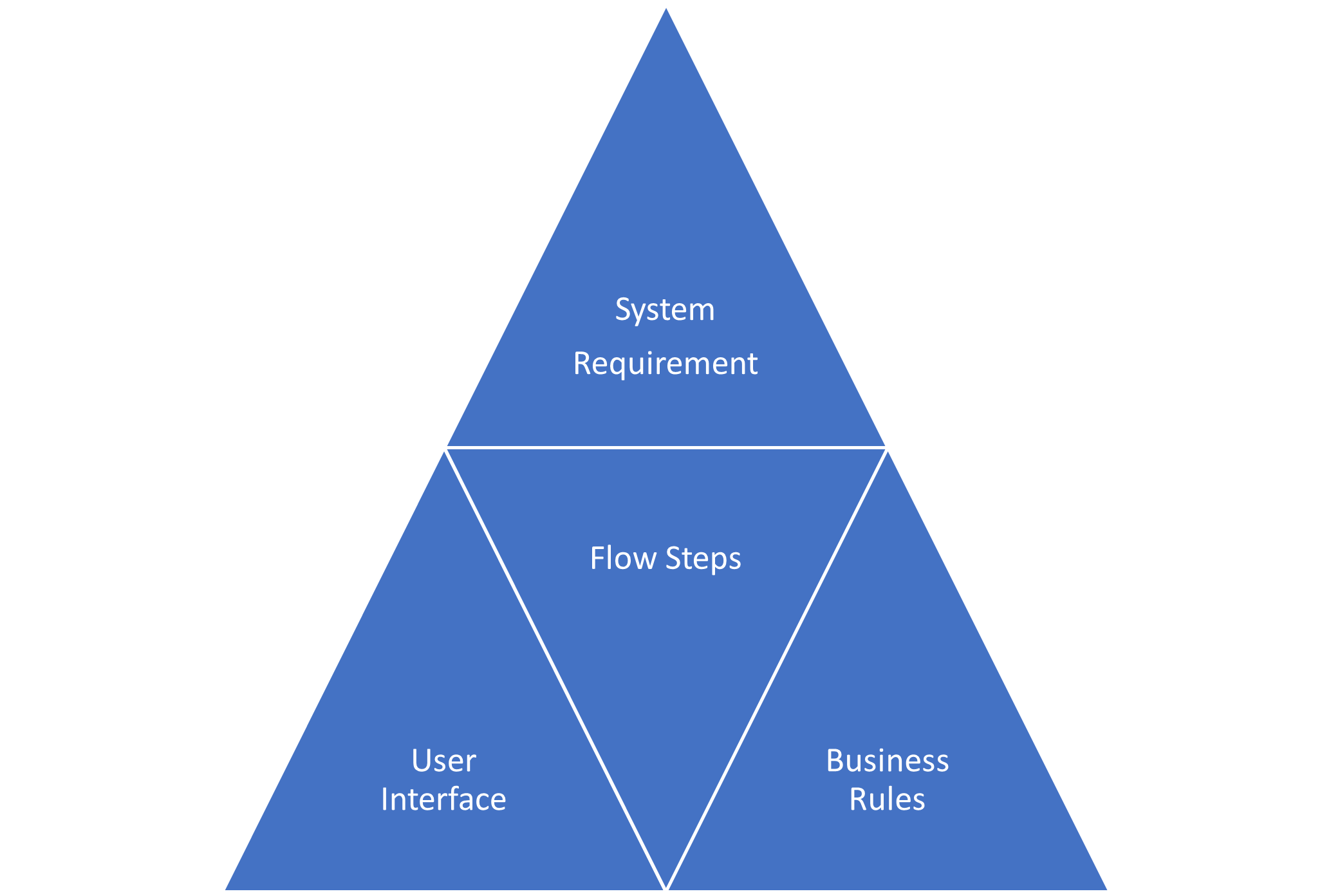
Use cases and user stories come together in the steps of a use case i.e., supporting the flow, whether it is worth elaborating main flows and alternate flows within a single business use case is debatable. The key objective is to keep the use case as simple as possible whilst demonstrating how the requirement will be met, so adding exception flows may cause confusion at this stage.
It is also possible that an existing feature will support a requirement without the need for a change story to be introduced; it is valid to include this feature in the use case as a step to demonstrate how this will work. For an existing feature, screen shots can be included and marked up with candidate changes; for a new feature then a wireframe mock-up may be included where a user interface is needed to support a step in the process.
Tip – Catalogue Use Cases
It will be useful to have index of all the use cases that includes a status to show which ones have been published and review with SMEs. We managed our use case catalogue within Confluence using custom decision pages to provide and index view.
Requirements and Use Cases
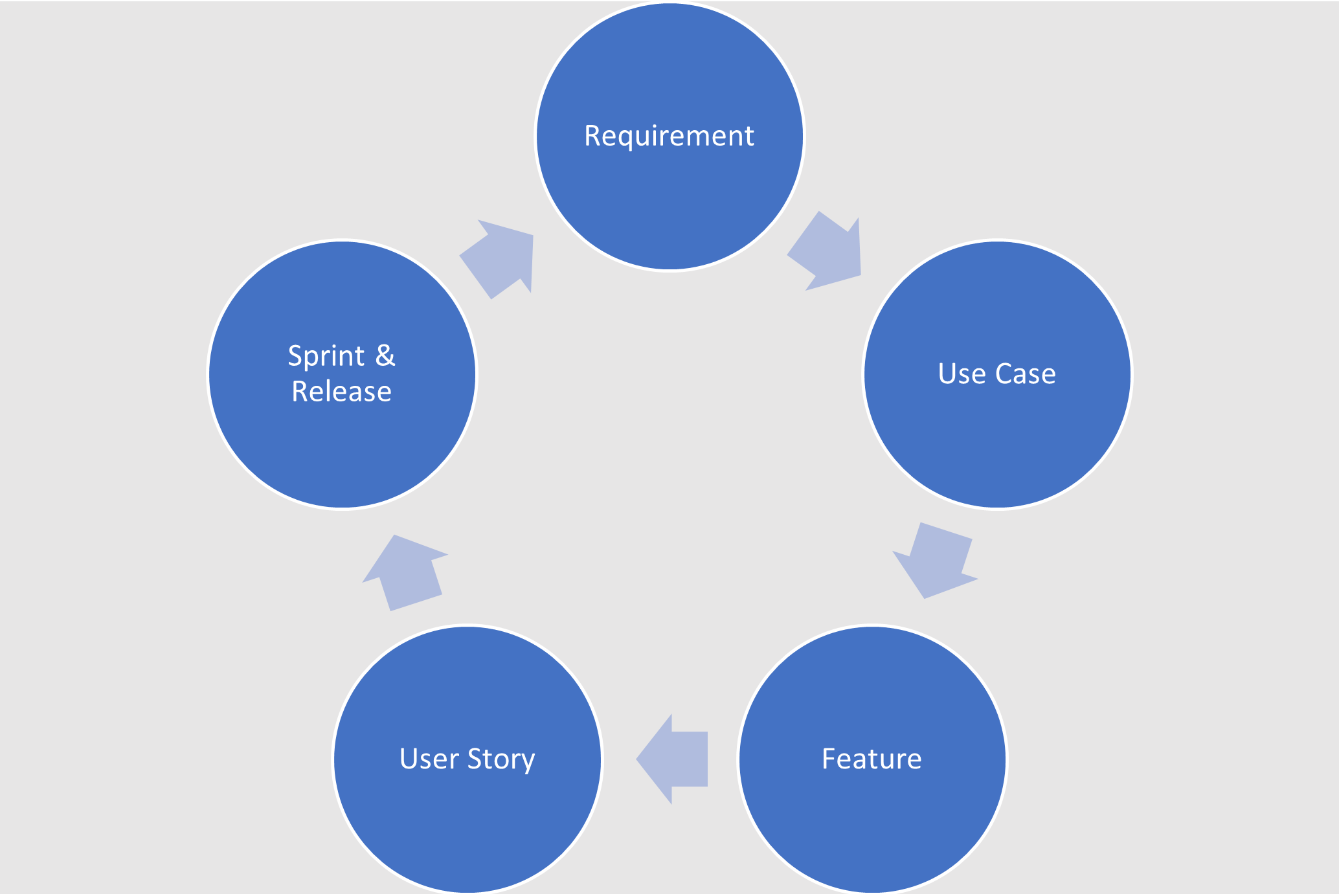
Now we are starting to build up a comprehensive set of product features that will meet the requirements and these will have been validated with SMEs; so, we are in a good position to elaborate the details of the user stories that will be needed to change existing features and add new features to the product.
Tip – Link Requirements
Linking requirements to use cases is a useful way to file the information, not all requirements will need separate use cases only those where confirmation is needed to better understand the underlying business need which can sometimes be obscured by a badly written requirement.
Conclusion
The use case is the glue that binds the product features and stories together into a comprehensive system that will meet the stated requirements; the user stories allow this requirement to be broken down into manageable features for delivery by agile sprint development teams.