Putting The Inclusion Use Case In Focus
 Introduction
Introduction
The circumstances that made me analyze the extension use case from the ground up (see [1]) also led me to examine the inclusion use case. Like the extension use case, the inclusion use case is at times misinterpreted and misapplied. Like the extension use case, once it’s understood from first principles, the inclusion use case has a more specialized purpose than is sometimes thought. This article mentions six fundamental points that contribute to creating quality use case models, with or without inclusion use cases.
Note: Section 16.1 of [2] uses “subject” to refer to “the system under consideration to which the use cases apply.” This article uses “system” instead.
Point 1: Include relationships cannot cross system boundaries
An include relationship — between a base use case and an inclusion use case — can only be defined between use cases of the same system.
This assertion is based on the following rationale.
Only associations can cross system boundaries
The association is a core element of a system’s use case diagram.
- An actor is always external to the system and a use case is always internal to the system.
- An actor and a use case can only be connected through an association, which therefore crosses the system boundary.
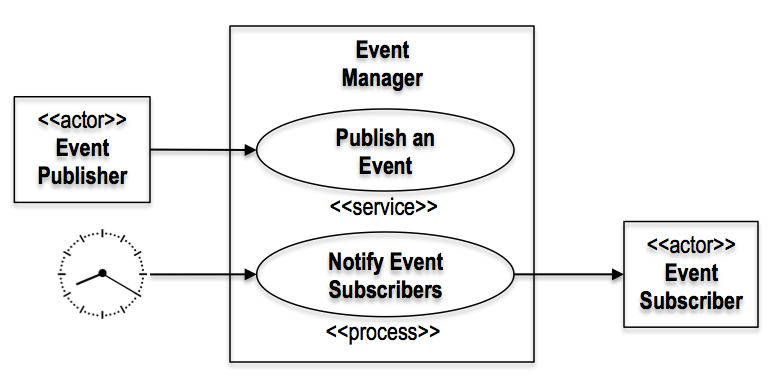
This is illustrated in the following diagram, which contains a “directed” association to show the flow of control (the actor initiates the interaction with the system).
Include relationships are not associations
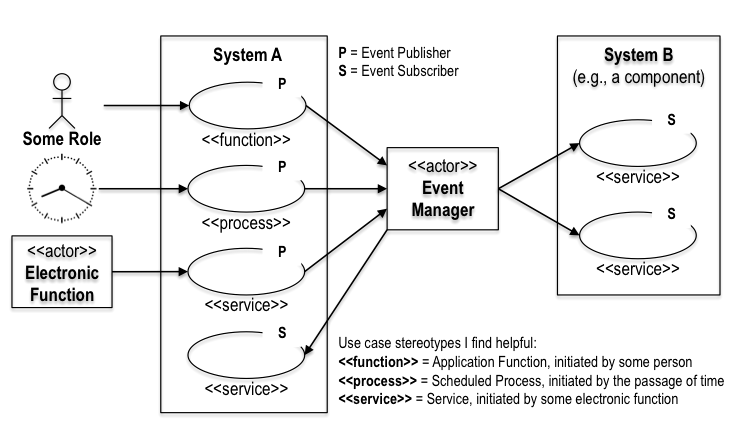
When use case A of one system can initiate use case B of a second system, then:
- In the use case diagram of the first system, the second system is shown as a supporting actor of use case A.
- In the use case diagram of the second system, the first system can be shown as the initiating actor of use case B.
Thus, a relationship between two use cases that crosses system boundaries can only be an association. Since an include relationship is not an association, it cannot cross system boundaries, and can therefore only be used within a system boundary.
Supportive UML superstructure excerpts
Crucial excerpts from [2] that support the above are:
- “An Actor models […] an entity that interacts with the [system], but which is external to the [system].” Section 16.3.1, Description.
- “An actor can only have associations to use cases […]. Furthermore these associations must be binary.” Section 16.3.1, Constraints.
Point 2: Actors, associations and use cases are classes
This point connects points 1 and 3.
Classes
An association connects two classes (*).
- At its simplest, a class is a set of entities (objects, instances) of a certain type.
- An association represents that an instance in the one class can be connected to an instance in the other class through a link.
- A link is an instance of an association.
(*) In the UML an association is between “classifiers”, which is a broad category that includes the narrower (and somewhat informal) “classes” category used here.
Thus, a use case diagram represents a class view, where:
- An actor is a class of possible actor instances.
- A use case is a class of possible use case instances.
- The association between the actor and the use case is a class of links between actor instances and use case instances.
A class view is a model-time view and an instance view is a run-time view.
Throughout this article, “use case” and “use case class” are used interchangeably.
Supportive UML superstructure excerpt
A key excerpt from [2] that supports the above is:
- “An association describes a set of tuples whose values refer to typed instances. An instance of an association is called a link. A link is a tuple with one value for each end of the association, where each value is an instance of the type of the end.” Section 7.3.3.
Point 3: Inclusion use cases are not real use cases
Key UML superstructure excerpt
Section 16.3.5 of [2] states:
- “The include relationship is intended to be used when there are common parts of the behavior of two or more use cases [(*)]. This common part is then extracted to a separate use case, to be included by all the base use cases having this part in common.”
(*) Based on the preceding, this can be enhanced to “… two or more use cases of a single system.”
Thus, an inclusion use case is simply a common fragment lifted from two or more use case specifications and defined as the specification of a single inclusion use case. The inclusion use case is then referenced from the base use case specifications by an include statement in place of the original fragment.
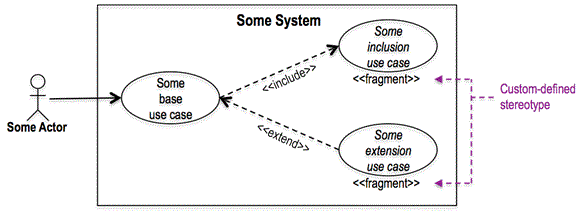
Inclusion use cases (and extension use cases) are fragments
Section 16.3.6 of [2] states that a use case “describes a complete usage of the [system]” by an initiating actor. Since, as shown above, inclusion use cases only represent portions of base use cases, an inclusion use case never “describes a complete usage of the [system]” and is therefore not a real use case. In [3] Jacobson proposes to call them “fragments” rather than use cases and even suggests a separate notation. Within the current UML notation, I use the custom-defined <
Inclusion use cases (and extension use cases) are abstract use cases
The UML refers to real and not real use cases as concrete and abstract use cases.
- A concrete use case is a use case that can be instantiated.
- An abstract use case is a use case that cannot be instantiated.
Concrete and abstract use cases in use case diagrams
- Any use case that has an association with an initiating actor is a concrete use case (*).
- At execution time, the initiation of the use case by an actor instance (within the actor class) creates a use case instance (within the use case class) (**).
- The use case instance behaves according to the use case specification, which is attached to the use case class and applies to all its instances.
- Any use case that does not have an association with an initiating actor is an abstract use case (*).
- At execution time, the specification of the abstract use case is combined with the specification of a related concrete use case, and the instance of the concrete use case behaves according to the combined specification.
- An abstract use case cannot be instantiated, so there will never be a use case instance that is solely based on an abstract use case.
(*) The exception is a generalized use case, which is outside the scope of this article.
(**) This applies if the actor is a person. When the actor is a system, the use case is initiated by an instance of a particular use case of that system, not by an instance of the system itself.
Regarding notation:
- A concrete use case’s name appears in straight font, an abstract use case’s name in italic font.
- An include relationship (and an extend relationship as well) appears as a dashed arrow (as opposed to a solid arrow used for a directed association) to convey that the relationship is between the specifications of the related use cases, not between instances of those use cases.
See the above diagram.
Public and private use cases
Because actors can only initiate a system’s concrete use cases, these are the only use cases that are visible outside the system, while the system’s abstract use cases are invisible outside the system. Thus, a system’s concrete use cases are its public use cases and the system’s abstract <
A key consequence of this is that if abstract use cases are to be introduced at all, they ought to be introduced after concrete use cases have been defined first.
Point 4: Inclusion use cases come in two varieties
One variety is the “textually included” inclusion use case. The inclusion use case’s specification text seamlessly connects with the specification texts of the base use cases, by referring directly to elements within those specification texts by name. Textually included inclusion use cases are context-aware.
- According to section 16.3.5 of [2], “the behavior of the [inclusion] use case is inserted into the behavior of the [base] use case.”
- For those of us who are old enough to remember, these are like copybooks in a COBOL program’s PROCEDURE DIVISION.
The other variety is the “parameterized” inclusion use case. The inclusion use case’s context is represented by input parameters, whose values are set by a base use case and used by the inclusion use case. The inclusion use case’s outcome is represented by output parameters, whose values are set by the inclusion use case and used by a base use case. Parameterized inclusion use cases are context-agnostic.
- Section 16.3.5 of [2] adds, “The [base] use case may only depend on the result (value) of the [inclusion] use case.”
- Continuing the COBOL analogy, these are like statically called subprograms.
Point 5: Inclusion use cases may be optional
A UML superstructure statement
Section 16.3.5 of [2] states:
- “Note that the [inclusion] use case is not optional, and is always required for the [base] use case to execute correctly.”
Cause for confusion
Some seem to interpret this to mean that an inclusion use case must be performed during each and every execution of a base use case.
Nothing is further from the truth and the truth is simple.
The simple truth
Whether an inclusion use case is mandatory or optional to a base use case depends on where in the base use case the fragment was defined that is now replaced with an include statement for the inclusion use case.
- If that fragment was part of the base use case’s unconditional flow (steps that always get executed), the inclusion use case is mandatory.
- If that fragment was part of a conditional flow (steps that get executed optionally), the inclusion use case is optional.
So what does the UML statement mean?
The purpose of the UML statement seems to be to contrast the include relationship with the extend relationship, as follows.
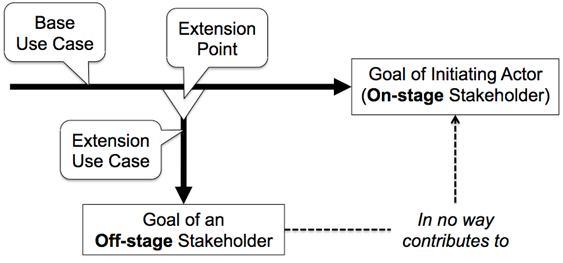
At an extension point (not for the entire base use case), the extension use case’s execution is optional.
- When the execution of a base use case reaches an extension point, an extension use case may or may not be inserted, because there may be a condition attached to the extend relationship.
However, at an “inclusion point” (not for the entire base use case), the inclusion use case’s execution is mandatory.
- When the execution of a base use case reaches an inclusion point (i.e., an include statement in the base use case), the inclusion use case will always be performed, because there is no provision for attaching a condition to the include relationship.
Point 6: Inclusion use cases are not intended for functional decomposition
The principle of creating an inclusion use case to represent “common parts of the behavior of two or more use cases [of a single system]” is at the same time a key argument against using inclusion use cases for functional decomposition, where a base use case would be decomposed into several inclusion use cases that would be included only in that base use case. Since such inclusion use cases would not be shared by “two or more use cases”, functional decomposition goes against the above principle.
This underlines that the key reason for introducing inclusion use cases is to optimize a system’s use case model through re-use of inclusion use cases.
- However, care must be taken not to take this to the extreme.
- Sometimes it’s “better” to introduce an inclusion use case and sometimes it’s “better” to describe a common fragment in multiple use case specifications.
In conclusion
These points may seem trivial to some, but being mindful of them inevitably results in better use case models. In fact, ignoring the first three may cause a larger omission. Due to space limitations, that must wait until later.
This article is about including an abstract use case, but that’s not the only use of the include relationship. Article [4] deals with including a concrete use case.
Don’t forget to leave your comments below.
References
[1] Willem Van Galen, Excavating the extension use case, 10 July 2012, (Part 1) and 24 July 2012, (Part 2).
[2] Object Management Group (OMG), OMG Unified Modeling LanguageTM (OMG UML), Superstructure, Version 2.4.1.
[3] Ivar Jacobson, Use Cases: Yesterday, Today, and Tomorrow, 20 November 2003.
[4] Willem Van Galen, The Include Relationship’s Other Use, 19 June 2013.

 Further observations
Further observations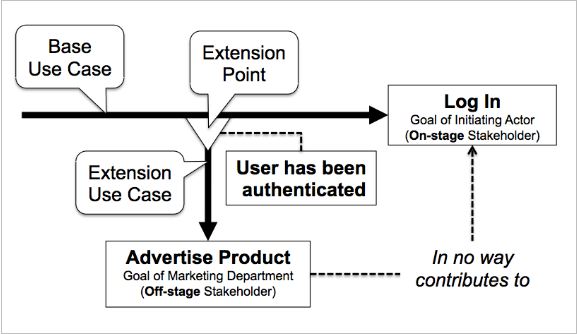


 contradictory information until I hit bedrock. The construct for which I felt the greatest need to do this is the extension use case (a close second was the inclusion use case, but that’s perhaps for another time). In this two-part article, I summarize my exploration and share my interpretation of what I found.
contradictory information until I hit bedrock. The construct for which I felt the greatest need to do this is the extension use case (a close second was the inclusion use case, but that’s perhaps for another time). In this two-part article, I summarize my exploration and share my interpretation of what I found.